16 Conclusion
16.1 Introduction
Like the introduction, this concluding chapter contains few code chunks. The aim is to synthesize the contents of the book, with reference to recurring themes/concepts, and to inspire future directions of application and development. The chapter has no prerequisites. However, you may get more out of it if you have read and attempted the exercises in Part I (Foundations), try more advances approaches in Part II, and considered how geocomputation can help you solve work, research or other problems, with reference to the chapters in Part III (Applications).
The chapter is organized as follows. Section 16.2 discusses the wide range of options for handling geographic data in R. Choice is a key feature of open source software; the section provides guidance on choosing between the various options. Section 16.3 describes gaps in the book’s contents and explains why some areas of research were deliberately omitted, while others were emphasized. Next, Section 16.4 provides advice on how to ask good questions when you get stuck, and how to search for solutions online. Section 16.5 answers the following question: having read this book, where to go next? Section 16.6 returns to the wider issues raised in Chapter 1. In it we consider geocomputation as part of a wider ‘open source approach’ that ensures methods are publicly accessible, reproducible and supported by collaborative communities. This final section of the book also provides some pointers on how to get involved.
16.2 Package choice
A feature of R, and open source software in general, is that there are often multiple ways to achieve the same result. The code chunk below illustrates this by using three functions, covered in Chapters 3 and 5, to combine the 16 regions of New Zealand into a single geometry:
library(spData)
nz_u1 = sf::st_union(nz)
nz_u2 = aggregate(nz["Population"], list(rep(1, nrow(nz))), sum)
nz_u3 = dplyr::summarise(nz, t = sum(Population))
identical(nz_u1, nz_u2$geometry)
#> [1] TRUE
identical(nz_u1, nz_u3$geom)
#> [1] TRUEAlthough the classes, attributes and column names of the resulting objects nz_u1 to nz_u3 differ, their geometries are identical, as verified using the base R function identical().104
Which to use?
It depends: the former only processes the geometry data contained in nz so is faster, while the other options performed attribute operations, which may be useful for subsequent steps.
Whether to use the base R function aggregate() or the dplyr function summarise() is a matter of preference, with the latter being more readable for many.
The wider point is that there are often multiple options to choose from when working with geographic data in R, even within a single package. The range of options grows further when more R packages are considered: you could achieve the same result using the older sp package, for example. However, based on our goal of providing good advice, we recommend using the more recent, more performant and future-proof sf package. The same applies for all packages showcased in this book, although it can be helpful (when not distracting) to be aware of alternatives and being able to justify your choice of software.
A common choice, for which there is no simple answer, is between tidyverse and base R for geocomputation.
The following code chunk, for example, shows tidyverse and base R ways to extract the Name column from the nz object, as described in Chapter 3:
library(dplyr) # attach a tidyverse package
nz_name1 = nz["Name"] # base R approach
nz_name2 = nz |> # tidyverse approach
select(Name)
identical(nz_name1$Name, nz_name2$Name) # check results
#> [1] TRUEThis raises the question: which to use? The answer is: it depends. Each approach has advantages: base R tends to be stable, well-known, and has minimal dependencies which is why it is often preferred for software (package) development. The tidyverse approach, on the other hand, is often preferred for interactive programming. Choosing between the two approaches is therefore a matter of preference and application.
While this book covers commonly needed functions — such as the base R [ subsetting operator and the dplyr function select() demonstrated in the code chunk above — there are many other functions for working with geographic data, from other packages, that have not been mentioned.
Chapter 1 mentions 20+ influential packages for working with geographic data, and only a handful of these are covered in the book.
Hundreds of other packages are available for working with geographic data in R, and many more are developed each year.
As of 2024, there are more than 160 packages mentioned in the Spatial Task View and countless functions for geographic data analysis are developed each year.
The rate of evolution in R’s spatial ecosystem may be fast, but there are strategies to deal with the wide range of options. Our advice is to start by learning one approach in depth but to have a general understanding of the breadth of available options. This advice applies equally to solving geographic problems with R as it does to other fields of knowledge and application. Section 16.5 covers developments in other languages.
Of course, some packages perform better than others for the same task, in which case it’s important to know which to use. In the book we have aimed to focus on packages that are future-proof (they will work long into the future), high performance (relative to other R packages), well maintained (with user and developer communities surrounding them) and complementary. There are still overlaps in the packages we have used, as illustrated by the diversity of packages for making maps, as highlighted in Chapter 9, for example.
Overlapping functionality can be good.
A new package with similar (but not identical) functionality compared to an existing package can increase resilience, performance (partly driven by friendly competition and mutual learning between developers) and choice, both of which are key benefits of doing geocomputation with open source software.
In this context, deciding which combination of sf, tidyverse, terra and other packages to use should be made with knowledge of alternatives.
The sp ecosystem that sf superseded, for example, can do many of the things covered in this book and, due to its age, is built on by many other packages.
At the time of writing in 2024, 463 package Depend on or Import sp, up slightly from 452 in October 2018, showing that its data structures are widely used and have been extended in many directions.
The equivalent numbers for sf are 69 in 2018 and 431 in 2024, highlighting that the package is future proof and has a growing user base and developer community (Bivand 2021).
Although best known for point pattern analysis, the spatstat package also supports raster and other vector geometries and provides powerful functionality for spatial statistics and more (Baddeley and Turner 2005).
It may also be worth researching new alternatives that are under development if you have needs that are not met by established packages.
16.3 Gaps and overlaps
Geocomputation is a big area, so there are inevitably gaps in this book. We have been selective, deliberately highlighting certain topics, techniques and packages, while omitting others. We have tried to emphasize topics that are most commonly needed in real-world applications such as geographic data operations, basics of coordinate reference systems, read/write data operations and visualization techniques. Some topics and themes appear repeatedly, with the aim of building essential skills for geocomputation, and showing you how to go further, into more advanced topics and specific applications.
We deliberately omitted some topics that are covered in-depth elsewhere. Statistical modeling of spatial data such as point pattern analysis, spatial interpolation (e.g., kriging) and spatial regression, for example, are mentioned in the context of machine learning in Chapter 12 but not covered in detail. There are already excellent resources on these methods, including statistically orientated chapters in Pebesma and Bivand (2023c) and books on point pattern analysis (Baddeley, Rubak, and Turner 2015), Bayesian techniques applied to spatial data (Gómez-Rubio 2020; Moraga 2023), and books focused on particular applications such as health (Moraga 2019) and wildfire severity analysis (Wimberly 2023). Other topics which received limited attention were remote sensing and using R alongside (rather than as a bridge to) dedicated GIS software. There are many resources on these topics, including a discussion on remote sensing in R, Wegmann, Leutner, and Dech (2016) and the GIS-related teaching materials available from Marburg University.
We focused on machine learning rather than spatial statistical inference in Chapters 12 and 15 because of the abundance of quality resources on the topic. These resources include A. Zuur et al. (2009), A. F. Zuur et al. (2017) which focus on ecological use cases, and freely available teaching material and code on Geostatistics & Open-source Statistical Computing hosted at css.cornell.edu/faculty/dgr2. R for Geographic Data Science provides an introduction to R for geographic data science and modelling.
We have largely omitted geocomputation on ‘big data’ by which we mean datasets that do not fit on a high-spec laptop. This decision is justified by the fact that the majority of geographic datasets that are needed for common research or policy applications do fit on consumer hardware, large high resolution remote sensing datasets being a notable exception (see Section 10.8). It is possible to get more RAM on your computer or to temporarily ‘renting’ compute power available on platforms such as GitHub Codespaces, which can be used to run the code in this book. Furthermore, learning to solve problems on small datasets is a prerequisite to solving problems on huge datasets and the emphasis in this book is getting started, and the skills you learn here will be useful when you move to bigger datasets. Analysis of ‘big data’ often involves extracting a small amount of data from a database for a specific statistical analysis. Spatial databases, covered in Chapter 10, can help with the analysis of datasets that do not fit in memory. ‘Earth observation cloud back-ends’ can be accessed from R with the openeo package (Section 10.8.2). If you need to work with big geographic datasets, we also recommend exploring projects such as Apache Sedona and emerging file formats such as GeoParquet.
16.4 Getting help
Geocomputation is a large and challenging field, making issues and temporary blockers to work near inevitable. In many cases you may just ‘get stuck’ at a particular point in your data analysis workflow facing cryptic error messages that are hard to debug. Or you may get unexpected results with few clues about what is going on. This section provides pointers to help you overcome such problems, by clearly defining the problem, searching for existing knowledge on solutions and, if those approaches to not solve the problem, through the art of asking good questions.
When you get stuck at a particular point, it is worth first taking a step back and working out which approach is most likely to solve the issue. Trying each of the following steps — skipping steps already taken — provides a structured approach to problem solving:
- Define exactly what you are trying to achieve, starting from first principles (and often a sketch, as outlined below)
- Diagnose exactly where in your code the unexpected results arise, by running and exploring the outputs of individual lines of code and their individual components (you can can run individual parts of a complex command by selecting them with a cursor and pressing Ctrl+Enter in RStudio, for example)
- Read the documentation of the function that has been diagnosed as the ‘point of failure’ in the previous step. Simply understanding the required inputs to functions, and running the examples that are often provided at the bottom of help pages, can help solve a surprisingly large proportion of issues (run the command
?terra::rastand scroll down to the examples that are worth reproducing when getting started with the function, for example) - If reading R’s built-in documentation, as outlined in the previous step, does not help to solve the problem, it is probably time to do a broader search online to see if others have written about the issue you’re seeing. See a list of places to search for help below for places to search
- If all the previous steps above fail, and you cannot find a solution from your online searches, it may be time to compose a question with a reproducible example and post it in an appropriate place
Steps 1 to 3 outlined above are fairly self-explanatory but, due to the vastness of the internet and multitude of search options, it is worth considering effective search strategies before deciding to compose a question.
16.4.1 Searching for solutions online
Search engines are a logical place to start for many issues. ‘Googling it’ can in some cases result in the discovery of blog posts, forum messages and other online content about the precise issue you’re having. Simply typing in a clear description of the problem/question is a valid approach here but it is important to be specific (e.g., with reference to function and package names and input dataset sources if the problem is dataset specific). You can also make online searches more effective by including additional detail:
- Use quote marks to maximize the chances that ‘hits’ relate to the exact issue you’re having by reducing the number of results returned. For example, if you try and fail to save a GeoJSON file in a location that already exists, you will get an error containing the message “GDAL Error 6: DeleteLayer() not supported by this dataset”. A specific search query such as
"GDAL Error 6" sfis more likely to yield a solution than searching forGDAL Error 6without the quote marks - Set time restraints, for example only returning content created within the last year can be useful when searching for help on an evolving package
- Make use of additional search engine features, for example restricting searches to content hosted on CRAN with site:r-project.org
16.4.2 Places to search for (and ask) for help
In cases where online searches do not yield a solution, it is worth asking for help. There are many forums where you can do this, including:
- R’s Special Interest Group on Geographic data email list (R-SIG-GEO)
- The GIS Stackexchange website at gis.stackexchange.com
- The large and general purpose programming Q&A site stackoverflow.com
- Online forums associated with a particular entity, such as the RStudio Community, the rOpenSci Discuss web forum and forums associated with particular software tools such as the Stan forum
- Software development platforms such as GitHub, which hosts issue trackers for the majority of R-spatial packages and also, increasingly, built-in discussion pages such as that created to encourage discussion (not just bug reporting) around the sfnetworks package (see luukvdmeer/sfnetworks/discussions)
- Online chat rooms and forums associated with communities such as the rOpenSci and the geocompx community (which has a Discord server where you can ask questions), of which this book is a part
16.4.3 Reproducible examples with reprex
In terms of asking a good question, a clearly stated questions supported by an accessible and fully reproducible example is key (see also https://r4ds.hadley.nz/workflow-help.html).
It is also helpful, after showing the code that ‘did not work’ from the user’s perspective, to explain what you would like to see.
A very useful tool for creating reproducible examples is the reprex package.
To highlight unexpected behaviour, you can write completely reproducible code that demonstrates the issue and then use the reprex() function to create a copy of your code that can be pasted into a forum or other online space.
Imagine you are trying to create a map of the world with blue sea and green land. You could simply ask how to do this in one of the places outlined in the previous section. However, it is likely that you will get a better response if you provide a reproducible example of what you have tried so far. The following code creates a map of the world with blue sea and green land, but the land is not filled in:
If you post this code in a forum, it is likely that you will get a more specific and useful responses. For example, someone might respond with the following code, which demonstrably solves the problem, as illustrated in Figure 16.1:
library(sf)
library(spData)
# use the bg argument to fill in the land
plot(st_geometry(world), col = "green", bg = "lightblue")
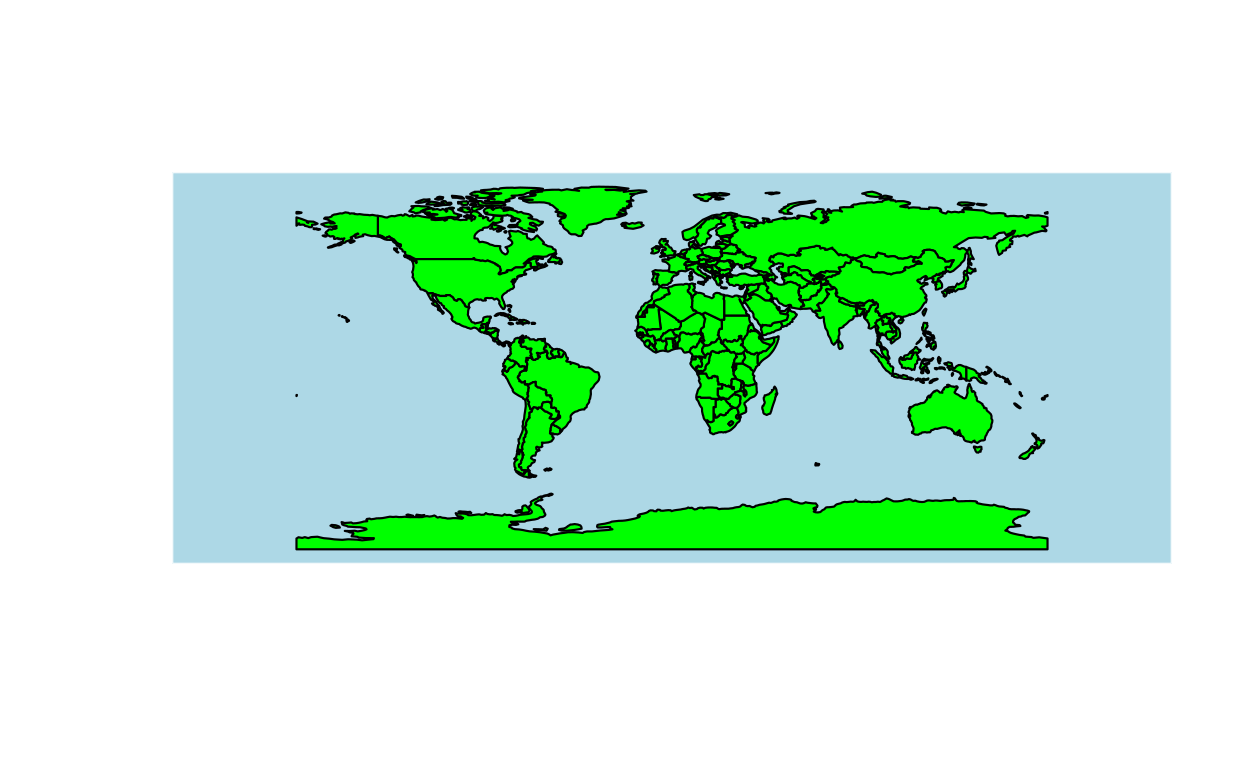
FIGURE 16.1: A map of the world with green land, illustrating a question with a reproducible example (left) and the solution (right).
Exercise for the reader: copy the above code, run the command reprex::reprex() (or paste the command into the reprex() function call) and paste the output into a forum or other online space.
A strength of open source and collaborative approaches to geocomputation is that they generate a vast and ever evolving body on knowledge, of which this book is a part. Demonstrating your own efforts to solve a problem, and providing a reproducible example of the problem, is a way of contributing to this body of knowledge.
16.4.4 Defining and sketching the problem
In some cases, you may not be able to find a solution to your problem online, or you may not be able to formulate a question that can be answered by a search engine. The best starting point in such cases, or when developing a new geocomputational methodology, may be a pen and paper (or equivalent digital sketching tools such as Excalidraw and tldraw which allow collaborative sketching and rapid sharing of ideas). During the most creative early stages of methodological development work software of any kind can slow down your thoughts and direct your thinking away from important abstract thoughts. Framing the question with mathematics is also highly recommended, with reference to a minimal example that you can sketch ‘before and after’ versions of numerically. If you have the skills and if the problem warrants it, describing the approach algebraically can in some cases help develop effective implementations.
16.5 Where to go next?
As indicated in Section 16.3, the book has covered only a fraction of the R’s geographic ecosystem, and there is much more to discover. We have progressed quickly, from geographic data models in Chapter 2, to advanced applications in Chapter 15. Consolidation of skills learned, discovery of new packages and approaches for handling geographic data, and application of the methods to new datasets and domains are suggested future directions. This section expands on this general advice by suggesting specific ‘next steps’, highlighted in bold below.
In addition to learning about further geographic methods and applications with R, for example with reference to the work cited in the previous section, deepening your understanding of R itself is a logical next step.
R’s fundamental classes such as data.frame and matrix are the foundation of sf and terra classes, so studying them will improve your understanding of geographic data.
This can be done with reference to documents that are part of R, and which can be found with the command help.start() and additional resources on the subject such as those by Wickham (2019) and Chambers (2016).
Another software-related direction for future learning is discovering geocomputation with other languages. There are good reasons for learning R as a language for geocomputation, as described in Chapter 1, but it is not the only option.105 It would be possible to study Geocomputation with: Python, C++, JavaScript, Scala or Rust in equal depth. Each has evolving geospatial capabilities. rasterio, for example, is a Python package with similar functionality as the terra package used in this book. See Geocomputation with Python, for an introduction to geocomputation with Python.
Dozens of geospatial libraries have been developed in C++, including well known libraries such as GDAL and GEOS, and less well known libraries such as the Orfeo Toolbox for processing remote sensing (raster) data. Turf.js is an example of the potential for doing geocomputation with JavaScript. GeoTrellis provides functions for working with raster and vector data in the Java-based language Scala. And WhiteBoxTools provides an example of a rapidly evolving command-line GIS implemented in Rust. Each of these packages/libraries/languages has advantages for geocomputation and there are many more to discover, as documented in the curated list of open source geospatial resources Awesome-Geospatial.
There is more to geocomputation than software, however. We can recommend exploring and learning new research topics and methods from academic and theoretical perspectives. Many methods that have been written about have yet to be implemented. Learning about geographic methods and potential applications can therefore be rewarding, before writing any code. An example of geographic methods that are increasingly implemented in R is sampling strategies for scientific applications. A next step in this case is to read-up on relevant articles in the area such as Brus (2018), which is accompanied by reproducible code and tutorial content hosted at github.com/DickBrus/TutorialSampling4DSM.
16.6 The open source approach
This is a technical book so it makes sense for the next steps, outlined in the previous section, to also be technical. However, there are wider issues worth considering in this final section, which returns to our definition of geocomputation. One of the elements of the term introduced in Chapter 1 was that geographic methods should have a positive impact. Of course, how to define and measure ‘positive’ is a subjective, philosophical question, beyond the scope of this book. Regardless of your worldview, consideration of the impacts of geocomputational work is a useful exercise: the potential for positive impacts can provide a powerful motivation for future learning and, conversely, new methods can open-up many possible fields of application. These considerations lead to the conclusion that geocomputation is part of a wider ‘open source approach’.
Section 1.1 presented other terms that mean roughly the same thing as geocomputation, including geographic data science (GDS) and ‘GIScience’. Both capture the essence of working with geographic data, but geocomputation has advantages: it concisely captures the ‘computational’ way of working with geographic data advocated in this book — implemented in code and therefore encouraging reproducibility — and builds on desirable ingredients of its early definition (Openshaw and Abrahart 2000):
- The creative use of geographic data
- Application to real-world problems
- Building ‘scientific’ tools
- Reproducibility
We added the final ingredient: reproducibility was barely mentioned in early work on geocomputation, yet a strong case can be made for it being a vital component of the first two ingredients. Reproducibility:
- Encourages creativity by shifting the focus away from the basics (which are readily available through shared code) and towards applications
- Discourages people from ‘reinventing the wheel’: there is no need to re-do what others have done if their methods can be used by others
- Makes research more conducive to real world applications, by enabling anyone in any sector to apply your methods in new areas
If reproducibility is the defining asset of geocomputation (or command-line GIS) it is worth considering what makes it reproducible. This brings us to the ‘open source approach’, which has three main components:
- A command-line interface (CLI), encouraging scripts recording geographic work to be shared and reproduced
- Open source software, which can be inspected and potentially improved by anyone in the world
- An active user and developer community, which collaborates and self-organizes to build complementary and modular tools
Like the term geocomputation, the open source approach is more than a technical entity. It is a community composed of people interacting daily with shared aims: to produce high performance tools, free from commercial or legal restrictions, that are accessible for anyone to use. The open source approach to working with geographic data has advantages that transcend the technicalities of how the software works, encouraging learning, collaboration and an efficient division of labor.
There are many ways to engage in this community, especially with the emergence of code hosting sites, such as GitHub, which encourage communication and collaboration.
A good place to start is simply browsing through some of the source code, ‘issues’ and ‘commits’ in a geographic package of interest.
A quick glance at the r-spatial/sf GitHub repository, which hosts the code underlying the sf package, shows that 100+ people have contributed to the codebase and documentation.
Dozens more people have contributed by asking question and by contributing to ‘upstream’ packages that sf uses.
More than 1,500 issues have been closed on its issue tracker, representing a huge amount of work to make sf faster, more stable and user-friendly.
This example, from just one package out of dozens, shows the scale of the intellectual operation underway to make R a highly effective and continuously evolving language for geocomputation.
It is instructive to watch the incessant development activity happen in public fora such as GitHub, but it is even more rewarding to become an active participant. This is one of the greatest features of the open source approach: it encourages people to get involved. This book itself is a result of the open source approach: it was motivated by the amazing developments in R’s geographic capabilities over the last two decades, but made practically possible by dialogue and code sharing on platforms for collaboration. We hope that in addition to disseminating useful methods for working with geographic data, this book inspires you to take a more open source approach.